Inventory management is one of the most important components of any retail organization. Companies use different tools and technologies to optimize their supply chains, increase product availability, and reduce costs. Implementing a retail inventory management system that can process large amounts of data quickly, effectively, and efficiently has become paramount for retail organizations to sustain in a BANI (Brittle, Anxious, Non-linear, Incomprehensible) world.
A custom inventory management system (IMS) written in a non-optimized scripted programming language, such as Python, can quickly become overloaded. The effects of overloading are especially apparent when it needs advanced analytics operations on distributed data. It’s common for retail chains to have a system that provides daily or even hourly product availability information. Unavailability of promote information to the management may lead to bad decision-making, loss of sales, and wasted inventory.
Problems with the Custom Python IMS
Let’s assume a scenario where a large retail chain uses a custom IMS written in Python, using Pandas and the NumPy and SciPy modules. Since the source data comes from hundreds or perhaps even thousands of store outlets, you may assume the possibilities of having multiple duplications, causing the custom IMS to get bogged down and taking hours to process.
Let’s also assume that the application will occasionally fail during data processing, which will lead to re-running of the entire process. It’s also common for large retail chains to host their applications on a public cloud, which means they incur substantial cost overruns.
Another problem with many custom applications is that they are monolithic and symmetric. Many developers believe in creating ‘one-size-fits-all’ solutions, while single monolithic applications are designed to run linearly, one line after another, from start to finish.
How You Can Achieve an Immediate Performance Boost
Our Information Analytics team used PySpark to re-engineer a new solution that delivers immediate benefits. We broke the original monolithic IMS into multiple scripts, where each script was responsible for its data. It was done by simply storing data in intermediate tables.
Then, we developed one primary job to manage individual scripts. This job allows you to run any script and supply required parameters and data storage locations. The data is easily configurable at the primary level. Further, each script is smart enough that, if necessary, you could run individual scripts without tweaking parameters or configuration.
Faster Processing Leads to Cost Savings
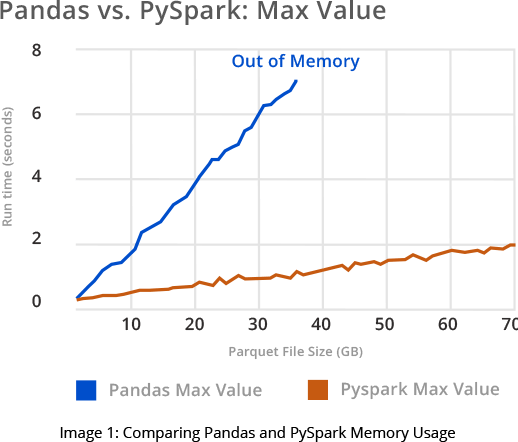
Optimized PySpark-enabled code helps you gain predictive analysis-based solutions. The enormous speed increase leads to significant overall cloud computing cost savings of up to 50%. As seen from the graph shown in Image 1, switching from Pandas to PySpark results in massive memory savings over time. In a cloud environment, memory savings translates into actual monetary savings.
Duplicate data and job and node failure are now a thing of the past, resulting in a technology implementation that makes future product availability analytics readily accessible. Our experts modularize the code to maintain its original functionality while delivering even better performance at the code and job level.
Implementing the PySpark technology and code modularization with better scalability helps businesses gain insights into the item, date, and hour-level product availability at a store level while remaining cost-effective. Also, since PySpark provides Pandas API, most custom stand-alone code do not need to be rewritten, which results in additional time and cost savings.
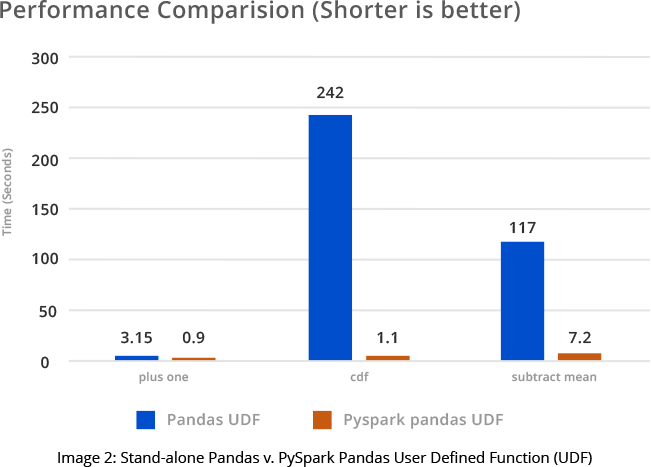
Data Analytics
Let’s consider a scenario where our data engineering and analytics team processed the last three years’ of store data by incorporating Azure, PySpark, Python, NumPy, Pandas, SciPy and some algorithms (built-in and designed) to predict product availability.
PySpark provides a gateway from Python to Apache Spark and provides near-real-time data anaytics along with distributed processing.
Most major cloud service providers, such as Microsoft Azure, AWS (Amazon Web Services), or GCP (Google Cloud Platform), provide support for Spark. A cloud-based Spark implementation opens the door to high-speed data analytics processing of large volumes of data.
Spark, on a cloud-based Azure Databricks platform, is highly scalable and supports parallel data processing of petabytes of streaming data, machine learning (ML) algorithms, and SQL analytics.
For analyzing the tabular data, we used Pandas and NumPy for numerical data, linear algebra, and matrices. For statistical concepts, complex operations, such as algebraic functions, various numerical algorithms SciPy is used to solve the same.
By combining above said technologies, you may conduct a near-real-time deep analysis of internal data using sales, inventory, and the shelf-life of the products or items to make accurate predictions of product availability.
Conclusion
Our unique approach to classic retail inventory management yields a tremendous ROI. This solution drastically lowers cloud resource costs, reduces inventory wastage, and improves sales. The optimization techniques discussed not only vastly reduce the time it takes to get results but deliver more accurate results as duplicate data is eliminated. Businesses benefit from this approach as they can now measure how often a product is in the right place at the right time. This allows them to make a sale on customer demand, resulting in an improved top line.
You may also read how we helped a large retail beverage chain resolve product availability issues in our case study, “Predictive Analytics Using PySpark Can Solve Your Product Availability Problems.”

Shubham Aggarwal
Practice - Information Analytics

Vijaykumar Kalangi
Practice - Information Analytics
Published Jun 19 2023